Batch Data Synchronization
Batch data synchronization is used when you want to synchronize database tables, views virtual tables, or saved queries. The selection of the pair of objects meant for synchronization is done by the user.
For example, you are moving your installment loan implementation to FintechOS and want to extract, transform, and load customer billing data into the FintechOS platform from a remote system each week (ongoing).
Batch data synchronization allows you to import and export data into and out of the FintechOS platform. While using this integration, you must take into consideration that these synchronizations can involve large amounts of data and can interfere with the end user operations during business hours.
The below table shows you how to store data, when to refresh it, if the data supports primary business processes, and if there are any reporting requirements that are impacted by the data availability in FintechOS.
| Procedure | Fit | Description |
|---|---|---|
| Data Pipes replication | Good | Data Pipes extract data from external data sources and replicates it in the FintechOS database or other data management systems. By replicating and synchronizing data from outside sources, you can work with external data sets as if they were native FintechOS database records. Data Pipes can also be used when updating data in the remote systems. It extracts and transforms the data from the FintechOS database and updates the remote system. |
| Remote call-in | Suboptimal | FintechOS enables you to generate clients using WebAPI import capabilities:
|
| FintechOS Callout | Suboptimal | It’s possible for FintechOS to call into a remote system and perform updates to data as they occur. However, this causes considerable on-going traffic between the two systems. A greater emphasis should be placed on error handling and locking. This pattern has the potential for causing continual updates, which has the potential to impact performance for end users. |
When implementing this pattern, the most effective external technologies are ETL or ELT tools but in a cloud environment due to the security concerns of exposing direct connection database over the internet.
The below table highlights the highlights the FintechOS properties best suited for the batch data synchronization pattern.
| Property | Mandatory | Desirable |
Not Required |
|---|---|---|---|
| Event handling | X | ||
| Protocol conversion | X | ||
| Translation and transformation | X | X | |
| Queuing and buffering | X | ||
| Synchronous transport protocols | X | ||
| Asynchronous transport protocols | X | ||
| Mediation routing | X | ||
| Process choreography and service orchestration | X | ||
| Transactionality (encryption, signing, reliable delivery, transaction management) | X | ||
| Routing | X | ||
| Extract, transform, and load | X |
| Location | Method | Strategy Description |
|---|---|---|
| Batch data updates from FintechOS | Error handling | If an error occurs during the write operation, implement a retry process for errors that are not infrastructure-related. If the failure continues, standard processing using control tables/ error tables should be implemented in the context of an ETL operation to:
|
| Error recovery | If the operation succeeds but there are failed records in the external system, it’s up to the remote system to request the resending of data. | |
| Read from FintechOS using DATA PIPES | Error handling | If an error occurs during the write operation, implement a retry process for errors that are not infrastructure-related. If the failure continues, standard processing using control tables/ error tables should be implemented in the context of an ETL operation to:
|
| Error recovery | Restart the ETL process to recover from a failed read operation. |
|
| Write to FintechOS using API calls | Error handling | There is a combination of factors that can determine errors to occur during a write operation. API calls return the below listed result set. If necessary, this information can be used to retry the write process.
|
| Error recovery | Since it’s a write operation transactionality must be covered and in case of an error everything should be rolled back. |
The following security considerations are specific to the calls made using this pattern.
- Standard encryption should be used to keep password access secure.
- Use HTTPS protocol when calling FintechOS APIs. You can also proxy traffic to the FintechOS APIs through an on-premise security solution.
- 3rd party ETL tools are not desired in a cloud-based environment due to greater risk of exposing direct Oracle JDBC connection via the internet.
The below diagram illustrates the data flow when sending updates to a remote database using the ELT (Extract Load Transform) concept.
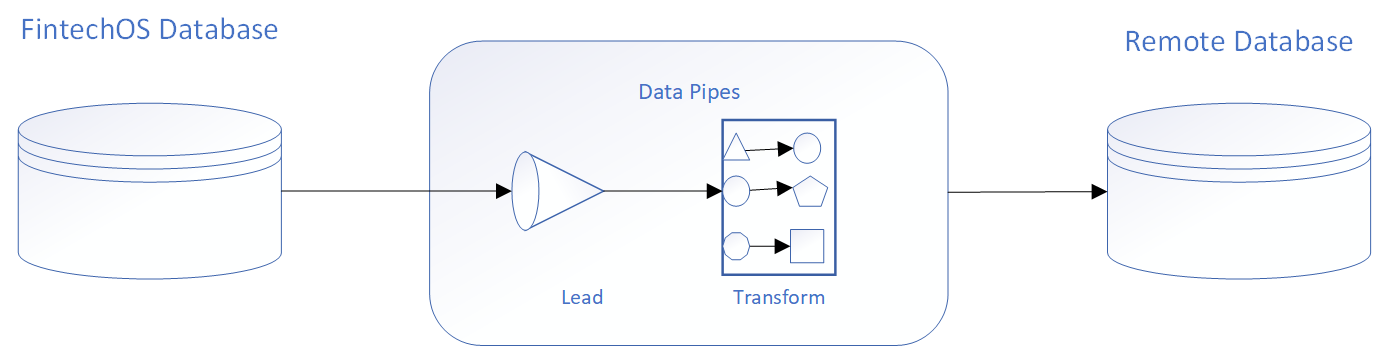
The following scenarios describe how you can integrate externally sourced data with the FintechOS platform.
- If the external system is the data master: in this case, you can have a data warehouse or data mart that aggregates the data before the data is imported into the FintechOS platform.
- If the FintechOS platform is the data master: in this case, the FintechOS platform produces the data and publishes the updates to the external system.
Consider the following to gain maximum benefit from data synchronization capabilities when using an ETL tool:
- Use primary keys from both systems to match incoming data.
- Use specific methods to extract only updated data.
- For child records in a master-detail or lookup relationship importing, group the imported data using its parent key at the source to avoid locking.
For example, when importing contact data, make sure you group the contact data by the parent account key so the maximum number of contacts for a single account can be loaded in one API call. - For post-import processing, only process data selectively.
An insurance company uses a central data repository batch process that assigns certain tasks to individual sales reps and teams. This information needs to be imported into FintechOS every night.
The customer has decided to update the data into the FintechOS database using the DATA PIPES integration. The solution works as follows:
• A cron-like scheduler executes a batch job that assigns tasks to users and teams.
• The batch job runs and starts the transfer to the DATA PIPES platform.
• DATA PIPES transforms the data and then updates it into the FintechOS database.